![]()
FlySearch: Exploring how vision-language models explore
Adam Pardyl, Dominik Matuszek, Mateusz Przebieracz, Marek Cygan, Bartosz Zieliński, Maciej Wołczyk
Tl;dr
A benchmark for evaluating vision-language models in simulated 3D, outdoor, photorealistic environments. Easy for humans, hard for state-of-the-art VLMs / MLLMs.
Leaderboard
| Model | FS-1 | FS-Anomaly-1 | FS-2 | |
|---|---|---|---|---|
| Forest (%) | City (%) | Overall (%) | City (%) | |
| Human (untrained) | -- | 66.7 ± 4.5 | -- | 60.8 ± 6.9 |
| Gemini 2.0 flash | 42.5 ± 3.5 | 41.5 ± 3.5 | 35.5 ± 3.4 | 6.0 ± 1.1 |
| Claude 3.5 Sonnet | 52.0 ± 3.5 | 30.5 ± 3.3 | 27.5 ± 3.2 | 6.5 ± 1.2 |
| GPT-4o | 45.5 ± 3.5 | 33.5 ± 3.3 | 27.0 ± 3.1 | 3.5 ± 0.9 |
| Pixtral-Large | 38.0 ± 3.4 | 21.5 ± 2.9 | 15.0 ± 2.5 | 3.0 ± 0.8 |
| Qwen2-VL 72B | 16.5 ± 2.6 | 18.0 ± 2.7 | 7.5 ± 1.9 | -- |
| Llava-Onevision 72b | 12.5 ± 2.3 | 6.5 ± 1.7 | 8.5 ± 2.0 | -- |
| Qwen2.5-VL 7B | 6.0 ± 1.7 | 1.5 ± 0.9 | 2.8 ± 1.2 | 0.0 ± 0.0 |
| InternVL-2.5 8B MPO | 2.5 ± 1.1 | 1.5 ± 0.9 | 3.5 ± 1.3 | -- |
| Llava-Interleave-7b | 0.0 ± 0.0 | 1.5 ± 0.9 | 0.0 ± 0.0 | -- |
| Phi 3.5 vision | 0.0 ± 0.0 | 0.0 ± 0.0 | 0.0 ± 0.0 | -- |
Motivation: Vision-Language Models for Embodied AI exploration
Can Vision-Language Models (VLMs) perform active, goal-driven exploration of real-world environments?
- The real world is messy and unstructured. Uncovering critical information and decision-making requires curiosity, adaptability, and a goal-oriented mindset.
- VLMs offer great zero-shot performance in many difficult tasks ranging from image captioning to robotics.
- The ability of VLMs to operate in realistic, open-ended environments remains largely untested.
Idea: Evaluate VLM exploration skills in 3D open world scenarios
FlySearch -- a new benchmark that evaluates exploration skills using vision-language reasoning.
- Task: locate an object specified in natural language or by visual examples.
- Embodied interaction: control an Unmanned Aerial Vehicle (UAV), observing images obtained from successive locations of the UAV and providing text commands that describe the next move.
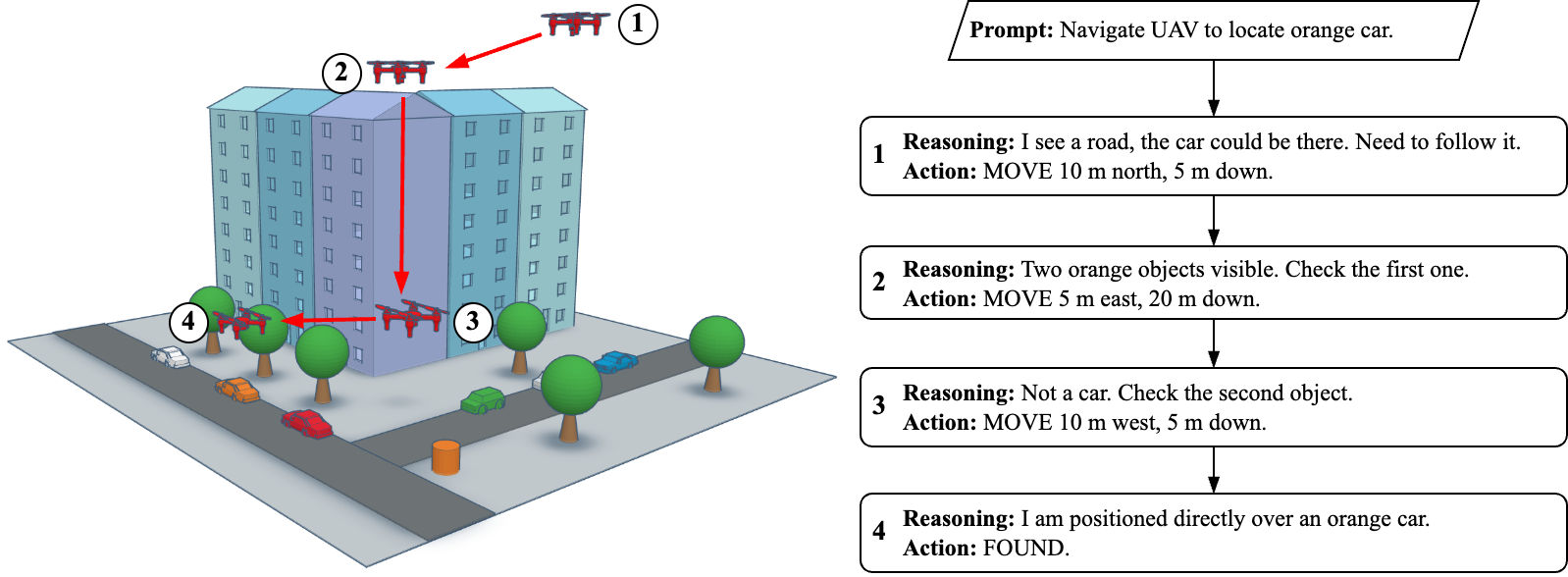
Realistic vision-language exploration benchmark
- High-fidelity outdoor environment built with Unreal Engine 5, enabling realistic and scalable evaluation of embodied agents in complex, unstructured settings.
- A suite of object-based exploration challenges designed to isolate and measure the exploration capabilities of VLMs and humans in open-world scenarios.
- Procedurally generated. We can generate an infinite number of vastly different test scenarios.
- Easy to solve for a human, while challenging for popular VLMs. We identify consistent failure modes across vision, grounding, and reasoning.
Our benchmark consists of two types of evaluation environments, forest and city. For each environment, we can generate an infinite number of procedurally generated test scenarios.
-
Forest environment

-
City environment

Standardized evaluation set
We define three levels of difficulty of FlySearch and provide a test set of generated scenarios:
- FS-1: The target is visible from the starting position, but can be just a few pixels wide in the initial view. The object is described by text (e.g. "a red sport car").
- FS-Anomaly-1: The target object is an easy-to-spot anomaly (e.g. a flying saucer/UFO). The object description is not given to the model, the task is to look for an anomaly. Other settings as in FS-1.
- FS-2: The object can be hidden behind buildings or be far away from the staring position. Additional visual preview of the object is given to the model at the start.
Evaluation pipeline
FlySearch consists of three parts besides the vision-language model: the simulator, the evaluation controller, and the scenario generator.
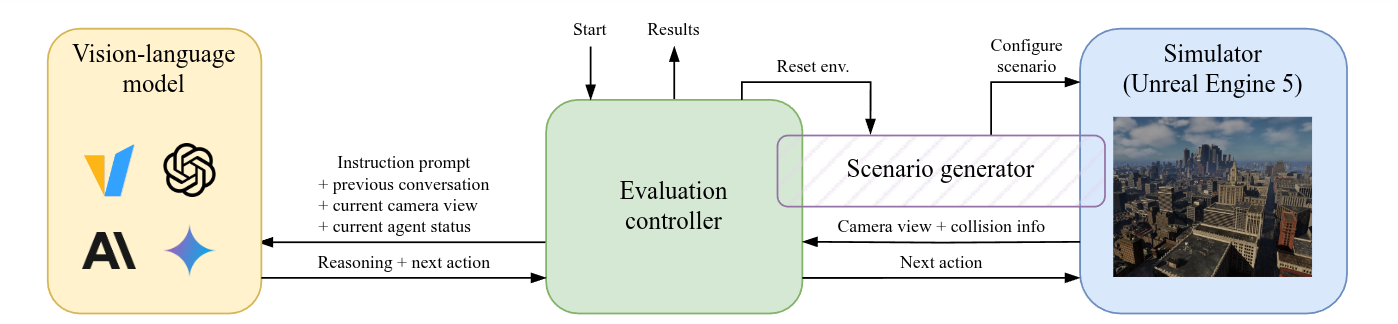
Benchmark environment details
- Initial prompt: Describes the target, provides information on how to perform actions, and the success conditions.
- Observations: During exploration, the model is provided with the current camera view of the UAV (500 × 500 px RGB image, downward-facing camera) and current altitude.
- Action: Relative movement coordinates or the FOUND action (as text), preceded by an unlimited number of reasoning tokens.
- Success condition: The agent has the target's center in its view, is at most 10 meters above it, and responds with FOUND.
Example trajectory
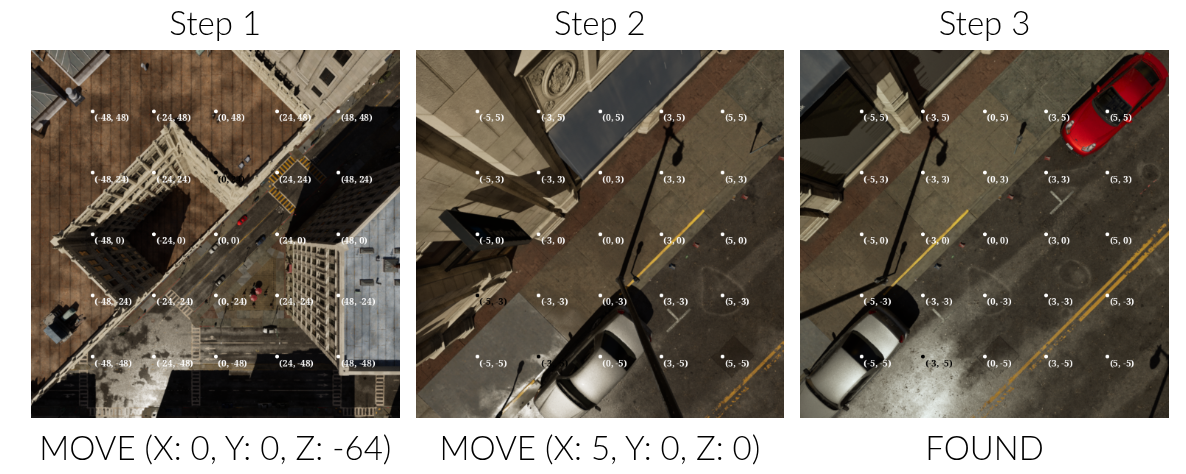
Example of a successful trajectory in FS-1 performed by GPT-4o. The agent navigates to red sports car object by first descending and then moving to the right. The first row shows the model’s visual inputs, and the second actions it has taken. Note the presence of the grid overlay on images.
Acknowledgements
Citation
@misc{pardyl2025flysearch,
title={FlySearch: Exploring how vision-language models explore},
author={Adam Pardyl and Dominik Matuszek and Mateusz Przebieracz and Marek Cygan and Bartosz Zieliński and Maciej Wołczyk},
year={2025},
eprint={2506.02896},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2506.02896},
}
Contact
For questions, please open an issue on GitHub or contact Adam Pardyl -- adam.pardyl <at> doctoral.uj.edu.pl.




